
シリーズ: Claudeで変わる仕事術 上級・第6弾 / 前回:上級・第5弾 Claudeの答えを証跡にする。「根拠ごと返す」プロンプト設計
毎朝、同じ確認をしている人は多い。
ニュースを見る。 参考URLを見る。 業務に関係するPDFが更新されていないか見る。 必要な商品や数値だけ確認する。 気になる点をメモする。
ひとつひとつは小さい。
でも、毎日やると重い。
しかも、朝は忙しい。
メールも来る。 会議もある。 チャットも鳴る。
その中で、毎朝同じページを開いて、同じ確認をする。
これは、Claude Codeに任せやすい仕事だ。
ただし、全部をAIに丸投げしない。
見る場所を決める。 保存先を決める。 ログを残す。 不明点を残す。 最後は人間が読む。
この形にすると、毎朝の確認業務は「気合い」ではなく「仕組み」になる。
今回は、上級編の総合実践だ。
第3弾で作ったHeadless。 第4弾で作ったLoop。 第5弾で作ったログ・証跡。
これらをつなぎ、ニュース・参考URL・CBP最新PDF確認を、ひとつの朝レポートにする。
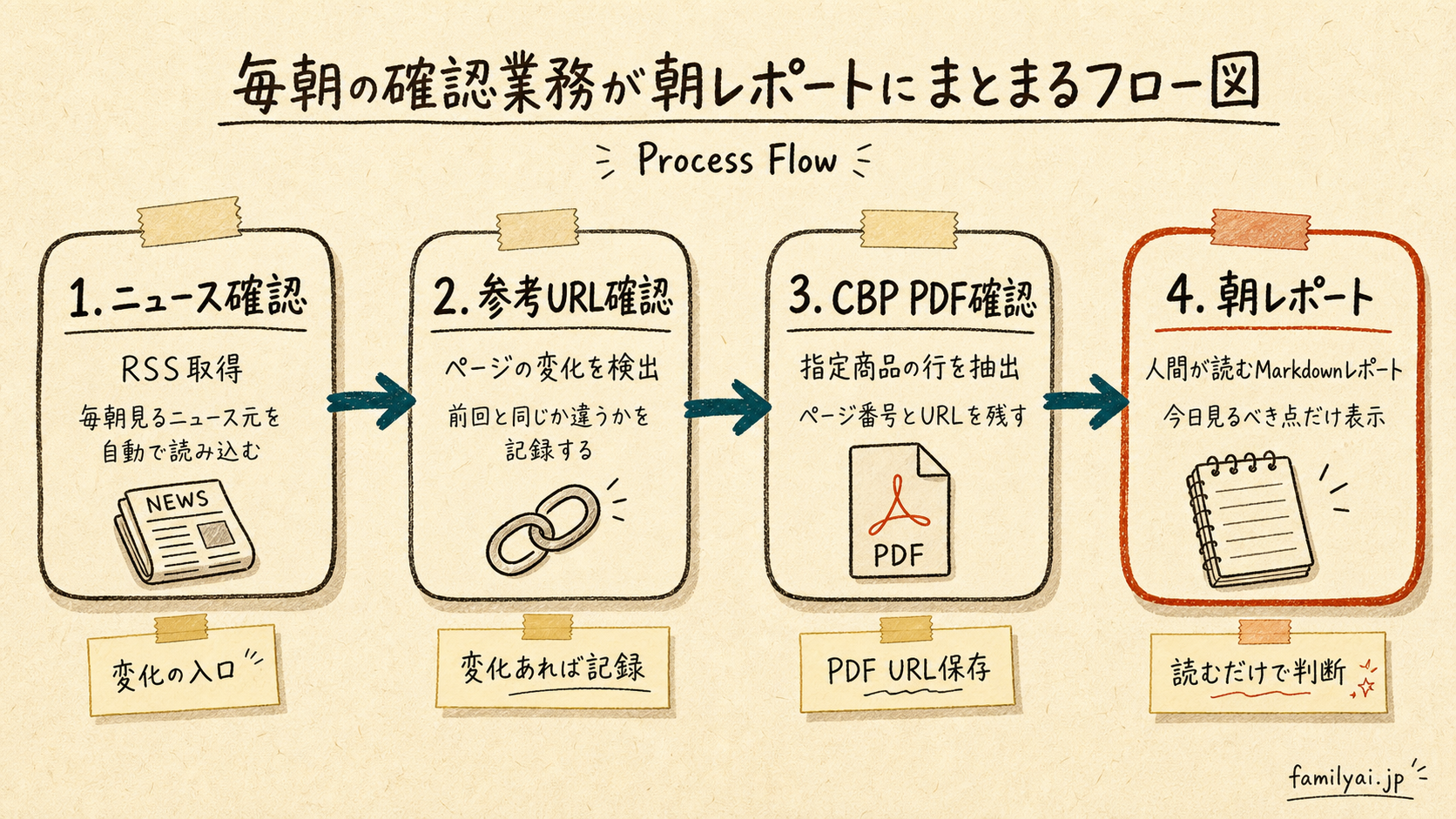
1. 毎朝確認業務は、AIに向いている
AIに向いている仕事には、特徴がある。
| 条件 | 内容 |
|---|---|
| 繰り返し発生する | 毎朝、毎週、毎月など |
| 見る場所が決まっている | ニュース元、参考URL、PDFページ |
| 出力の型が決まっている | 朝レポート、JSONログ、証跡 |
| 不明点を分けられる | 人間確認が必要な箇所を残せる |
毎朝の確認業務は、この条件に合う。
たとえば、輸入関連の仕事ならこうだ。
- 業界ニュースを見る
- 社内で使う参考URLを確認する
- CBPのCommodity Status Reportを見る
- 最新PDFが変わっていないか確認する
- 指定商品の残量や使用済み数量を見る
- PDF URLと該当ページを残す
AIに「何か重要なものを探して」と丸投げしない。
見る場所を先に決める。
その上で、Claude Codeに朝の確認を任せる。
2. 今回作るもの
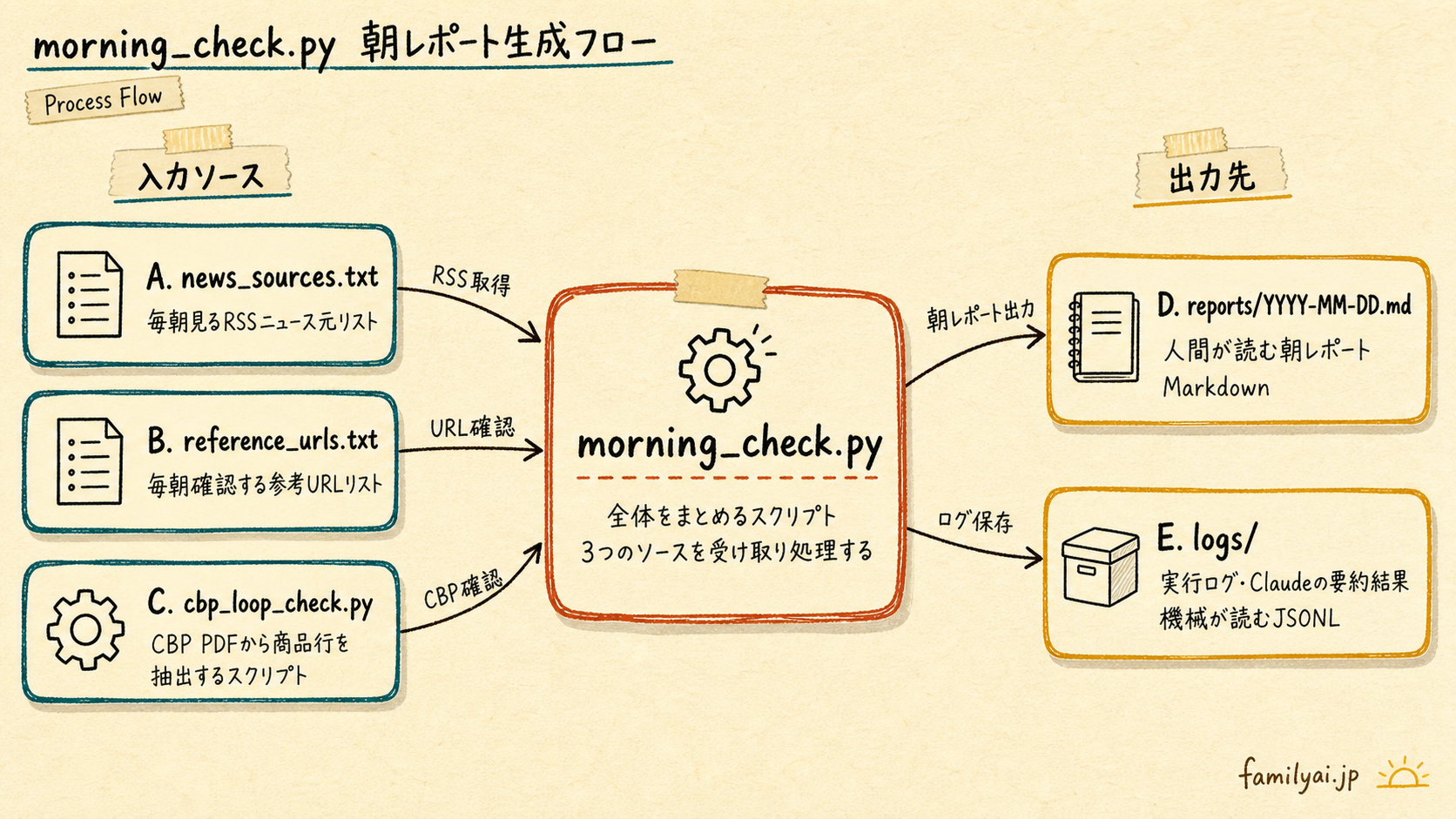
今回作るのは、朝レポートを作る小さな仕組みだ。
完成形はこうなる。
~/morning-check/
├── config/
│ ├── news_sources.txt
│ ├── reference_urls.txt
│ └── products.txt
├── scripts/
│ ├── morning_check.py
│ └── cbp_loop_check.py
├── reports/
│ └── 2026-06-27.md
├── logs/
│ ├── runs.jsonl
│ ├── errors.log
│ └── claude-results.jsonl
└── state.json
役割はこうだ。
| ファイル | 役割 |
|---|---|
news_sources.txt | 毎朝見るニュースRSS |
reference_urls.txt | 毎朝確認する参考URL |
products.txt | CBP PDFで確認する商品名 |
morning_check.py | 全体をまとめるスクリプト |
cbp_loop_check.py | CBP確認スクリプト(run_check.sh が呼んでいるPythonスクリプト) |
reports/YYYY-MM-DD.md | 人間が読む朝レポート |
logs/runs.jsonl | 機械が読む実行ログ |
logs/errors.log | 失敗ログ |
state.json | 前回確認した参考URLの状態 |
ここでは、ニュース取得も、参考URL確認も、CBP確認も、同じレポートに入れる。
ただし、全部を1つの巨大スクリプトにしない。
CBPのPDF確認は、これまで使ってきた cbp_loop_check.py に任せる。
今回の morning_check.py は、それらを束ねる役だ。
3. ハンズオン:毎朝確認業務を朝レポートにする
ステップ1:まずフォルダを作る
作業フォルダを作る。
mkdir -p ~/morning-check/config ~/morning-check/scripts ~/morning-check/reports ~/morning-check/logs
第4・5弾のCBPスクリプトを使う人は、次のようにコピーする。
cp ~/cbp-check/cbp_loop_check.py ~/morning-check/scripts/cbp_loop_check.py
この場合、実行には第4・5弾で作ったPython環境を使う。
~/cbp-check/.venv/bin/python -c "import pdfplumber; print('pdfplumber OK')"
pdfplumber OK と出れば、CBP確認まで同じ朝レポートに入れられる。
まだ第4・5弾をやっていない人は、ここは後回しでもいい。
今回のスクリプトは、cbp_loop_check.py が見つからない場合でも止まらない。
その代わり、朝レポートにこう残す。
CBP確認: skipped
備考: cbp_loop_check.py が見つからない
業務では、この考え方が大事だ。
一部ができない時に、全体を黙って止めない。
できなかったことを、できなかったと残す。
ステップ2:入力ファイルを作る
朝レポートで見る対象を、設定ファイルに分ける。
ニュース元
nano ~/morning-check/config/news_sources.txt
例。
Hacker News|https://hnrss.org/frontpage
左が表示名、右がRSSのURLだ。
実際の業務では、自分が毎朝見るニュースRSSに置き換える。
たとえば、業界団体、政府機関、社内で使っているニュース配信などだ。
参考URL
nano ~/morning-check/config/reference_urls.txt
例。
CBP Commodity Status Report|https://www.cbp.gov/document/report/commodity-status-report
ここには、毎朝見る参考ページを入れる。
ページの中身が変わったかどうかも、簡単に確認する。
商品名
nano ~/morning-check/config/products.txt
例。
SUGAR
RAW
CBPのPDFから確認したい商品名を入れる。
1行に1つだ。
ステップ3:Pythonスクリプトを作る
次に、朝レポートを作るスクリプトを書く。
nano ~/morning-check/scripts/morning_check.py
開いたら、次のコードを貼り付ける。
import hashlib
import json
import re
import subprocess
import sys
import xml.etree.ElementTree as ET
from datetime import datetime
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent.parent
CONFIG_DIR = BASE_DIR / "config"
REPORT_DIR = BASE_DIR / "reports"
LOG_DIR = BASE_DIR / "logs"
STATE_PATH = BASE_DIR / "state.json"
RUNS_JSONL = LOG_DIR / "runs.jsonl"
ERRORS_LOG = LOG_DIR / "errors.log"
CBP_SCRIPT = BASE_DIR / "scripts" / "cbp_loop_check.py"
def now_iso():
return datetime.now().isoformat(timespec="seconds")
def today():
return datetime.now().strftime("%Y-%m-%d")
def read_lines(path):
if not path.exists():
return []
lines = []
for line in path.read_text(encoding="utf-8").splitlines():
line = line.strip()
if line and not line.startswith("#"):
lines.append(line)
return lines
def load_state():
if STATE_PATH.exists():
return json.loads(STATE_PATH.read_text(encoding="utf-8"))
return {"references": {}}
def save_state(state):
STATE_PATH.write_text(
json.dumps(state, ensure_ascii=False, indent=2),
encoding="utf-8",
)
def append_jsonl(path, data):
path.parent.mkdir(parents=True, exist_ok=True)
with path.open("a", encoding="utf-8") as f:
f.write(json.dumps(data, ensure_ascii=False) + "\n")
def fetch_text(url):
return subprocess.check_output(
["curl", "-L", "--max-time", "30", "-s", url],
text=True,
errors="replace",
)
def split_label_url(line):
if "|" in line:
label, url = line.split("|", 1)
return label.strip(), url.strip()
return line, line
def collect_news():
items = []
for line in read_lines(CONFIG_DIR / "news_sources.txt"):
label, url = split_label_url(line)
try:
xml_text = fetch_text(url)
root = ET.fromstring(xml_text)
titles = []
for item in root.findall(".//item")[:3]:
title = item.findtext("title") or ""
link = item.findtext("link") or url
if title:
titles.append({"title": " ".join(title.split()), "url": link})
if not titles:
for entry in root.findall(".//{*}entry")[:3]:
title = entry.findtext("{*}title") or ""
link_node = entry.find("{*}link")
link = link_node.get("href") if link_node is not None else url
if title:
titles.append({"title": " ".join(title.split()), "url": link})
items.append({"source": label, "status": "ok", "items": titles})
except Exception as exc:
items.append({"source": label, "status": "error", "error": str(exc)})
return items
def collect_references(state):
results = []
state.setdefault("references", {})
for line in read_lines(CONFIG_DIR / "reference_urls.txt"):
label, url = split_label_url(line)
try:
html = fetch_text(url)
digest = hashlib.sha256(html.encode("utf-8", errors="replace")).hexdigest()
previous = state["references"].get(url, {})
changed = digest != previous.get("sha256")
title_match = re.search(r"<title[^>]*>(.*?)</title>", html, re.I | re.S)
title = " ".join(title_match.group(1).split()) if title_match else label
state["references"][url] = {
"label": label,
"sha256": digest,
"checked_at": now_iso(),
"title": title,
}
results.append({
"label": label,
"url": url,
"title": title,
"status": "changed" if changed else "unchanged",
})
except Exception as exc:
results.append({"label": label, "url": url, "status": "error", "error": str(exc)})
return results
def collect_cbp():
products = read_lines(CONFIG_DIR / "products.txt")
results = []
if not CBP_SCRIPT.exists():
return [{
"status": "skipped",
"note": "cbp_loop_check.py が見つからない",
}]
for product in products:
try:
output = subprocess.check_output(
[sys.executable, str(CBP_SCRIPT), product],
text=True,
errors="replace",
)
results.append(json.loads(output))
except Exception as exc:
results.append({"product": product, "status": "error", "error": str(exc)})
return results
def write_report(result):
REPORT_DIR.mkdir(parents=True, exist_ok=True)
path = REPORT_DIR / f"{today()}.md"
lines = [
f"# 朝レポート {today()}",
"",
f"- 確認日時: {result['checked_at']}",
"",
"## ニュース",
]
for source in result["news"]:
lines.append(f"### {source['source']}")
if source["status"] != "ok":
lines.append(f"- error: {source.get('error', '不明')}")
continue
for item in source["items"][:3]:
lines.append(f"- [{item['title']}]({item['url']})")
lines += ["", "## 参考URL"]
for ref in result["references"]:
lines.append(f"- {ref['status']}: [{ref['label']}]({ref['url']})")
lines += ["", "## CBP最新PDF確認"]
for cbp in result["cbp"]:
if cbp.get("status") == "skipped":
lines.append(f"- skipped: {cbp.get('note', 'cbp_loop_check.py が見つからない')}")
continue
pages = sorted(set(m["page"] for m in cbp.get("matches", []))) or "なし"
lines.append(
f"- {cbp.get('product', '不明')}: {cbp.get('status', '不明')} / "
f"該当件数 {cbp.get('match_count', '不明')} / "
f"ページ {pages}"
)
if cbp.get("pdf_url"):
lines.append(f" - PDF URL: {cbp['pdf_url']}")
if cbp.get("note"):
lines.append(f" - 備考: {cbp['note']}")
lines += ["", "## 今日、人間が見るべき点"]
attention = result["attention"] or ["大きなエラーはなし"]
for item in attention:
lines.append(f"- {item}")
path.write_text("\n".join(lines) + "\n", encoding="utf-8")
return str(path)
def main():
checked_at = now_iso()
state = load_state()
news = collect_news()
references = collect_references(state)
cbp = collect_cbp()
attention = []
if any(item.get("status") == "error" for item in news):
attention.append("ニュース取得でエラーあり")
if any(item.get("status") == "changed" for item in references):
attention.append("参考URLに変更あり")
if any(item.get("status") == "error" for item in cbp):
attention.append("CBP確認でエラーあり")
if any(item.get("status") == "needs_human" for item in cbp):
attention.append("CBP確認に人間確認が必要")
result = {
"checked_at": checked_at,
"news": news,
"references": references,
"cbp": cbp,
"attention": attention,
}
result["report_path"] = write_report(result)
save_state(state)
append_jsonl(RUNS_JSONL, result)
print(json.dumps(result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
try:
main()
except Exception as exc:
error = {"checked_at": now_iso(), "status": "error", "error": str(exc)}
append_jsonl(ERRORS_LOG, error)
print(json.dumps(error, ensure_ascii=False, indent=2))
raise SystemExit(1)
保存する。
nanoなら、Ctrl + O、Enter、Ctrl + X だ。
ステップ4:まずPythonだけで動かす
いきなりClaudeを挟まない。
まずPythonだけで動かす。
~/cbp-check/.venv/bin/python ~/morning-check/scripts/morning_check.py
うまくいくと、JSONが返る。
検証時は、次のような結果になった。
{
"checked_at": "2026-07-05T17:26:58",
"news": [
{
"source": "Hacker News",
"status": "ok",
"items": [
{
"title": "Is The Economist Always Wrong?",
"url": "https://economist.com/interactive/finance-and-economics/2026/07/02/is-the-economist-always-wrong"
},
{
"title": "EV Batteries Are Defying Expectations After Miles",
"url": "https://www.wsj.com/business/autos/ev-batteries-are-defying-expectations-after-hundreds-of-thousands-of-miles-8579de13"
},
{
"title": "sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)",
"url": "https://simonwillison.net/2026/Jul/5/sqlite-utils-fable/"
}
]
}
],
"references": [
{
"label": "CBP Commodity Status Report",
"url": "https://www.cbp.gov/document/report/commodity-status-report",
"title": "Commodity Status Report | U.S. Customs and Border Protection",
"status": "changed" } ],
"cbp": [
{
"checked_at": "2026-07-05T17:27:30",
"product": "SUGAR",
"status": "unchanged_pdf",
"previous_pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"match_count": 67,
"matches": [],
"note": "PDF and product unchanged, skipped extraction"
},
{
"checked_at": "2026-07-05T17:27:34",
"product": "RAW",
"status": "updated_pdf",
"previous_pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"match_count": 41,
"matches": [
{
"page": 2,
"line": "1701111RWSG05 Raw Sugar ARGENTINA - 202601 10/01/2025 09/30/2026 - 46260000 KG 41740389.62 90.23% OPEN -"
},
...
{
"page": 2,
"line": "1701111RWSG05 Raw Sugar INDIA - 202601 10/01/2025 09/30/2026 - 8606000 KG - 0.00% OPEN -"
}
],
"note": "PDF or product changed, extracted product lines"
}
],
"attention": [
"参考URLに変更あり"
],
"report_path": "/Users/junli/morning-check/reports/2026-07-05.md"
}
ここで見るのは、きれいな文章ではない。
まずは、データが取れているかを見る。
- ニュースが取れているか
- 参考URLが確認できているか
- CBP確認が動いたか、または備考として残ったか
report_pathが出ているか
この段階でエラーが出るなら、Claudeに要約させる前に直す。
ステップ5:朝レポートを見る
レポートを見る。
cat ~/morning-check/reports/$(date +%F).md
例。
# 朝レポート 2026-07-05
- 確認日時: 2026-07-05T17:26:58
## ニュース
### Hacker News
- [Is The Economist Always Wrong?](https://economist.com/interactive/finance-and-economics/2026/07/02/is-the-economist-always-wrong)
- [EV Batteries Are Defying Expectations After Miles](https://www.wsj.com/business/autos/ev-batteries-are-defying-expectations-after-hundreds-of-thousands-of-miles-8579de13)
- [sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)](https://simonwillison.net/2026/Jul/5/sqlite-utils-fable/)
## 参考URL
- changed: [CBP Commodity Status Report](https://www.cbp.gov/document/report/commodity-status-report)
## CBP最新PDF確認
- SUGAR: unchanged_pdf / 該当件数 67 / ページ なし
- PDF URL: https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf
- 備考: PDF and product unchanged, skipped extraction
- RAW: updated_pdf / 該当件数 41 / ページ [2]
- PDF URL: https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf
- 備考: PDF or product changed, extracted product lines
## 今日、人間が見るべき点
- 参考URLに変更あり
cbp_loop_check.py を置いていれば、CBP部分には次のような情報が入る。
- SUGAR: updated_pdf / 該当件数 67 / ページ [2, 3, 6, 7]
- PDF URL: https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_22.pdf
- 備考: PDF or product changed, extracted product lines
この形なら、朝の確認として使いやすい。
ニュースだけではない。 参考URLだけでもない。 PDF確認だけでもない。
毎朝見るものが、ひとつのレポートにまとまる。
ステップ6:Claudeに朝レポートを短くまとめさせる
PythonのMarkdownだけでも読める。
ただ、会社員の朝は忙しい。
最初に見る文章は、もっと短くていい。
そこで、Claudeに要約させる。
ここでは、ClaudeにPythonを実行させない。
先にPythonでJSONを作り、そのJSONをClaudeに渡す。
この方が、許可設定でつまずきにくい。
/Users/you は自分のユーザー名に置き換える。
/Users/you/cbp-check/.venv/bin/python /Users/you/morning-check/scripts/morning_check.py \
| claude --safe-mode -p "以下のJSONをもとに、会社員向けの朝レポートとして日本語で短くまとめて。必ず、確認日、重要ニュース、参考URLの変化、CBP最新PDF確認、商品ごとの確認結果、PDF URL、該当ページ、不明点、今日人間が見るべき点を含めて。数字は断定しすぎず、不明点は推測せず不明と書いて。" \
--output-format json \
--max-turns 5 \
--max-budget-usd 0.30
結果もログに残したい場合は、最後に追記する。
/Users/you/cbp-check/.venv/bin/python /Users/you/morning-check/scripts/morning_check.py \
| claude --safe-mode -p "以下のJSONをもとに、会社員向けの朝レポートとして日本語で短くまとめて。必ず、確認日、重要ニュース、参考URLの変化、CBP最新PDF確認、商品ごとの確認結果、PDF URL、該当ページ、不明点、今日人間が見るべき点を含めて。数字は断定しすぎず、不明点は推測せず不明と書いて。" \
--output-format json \
--max-turns 5 \
--max-budget-usd 0.30 \
>> /Users/you/morning-check/logs/claude-results.jsonl
この形なら、Claude側にBash権限を渡さなくていい。
Pythonで事実確認する
JSONをClaudeに渡す
Claudeは文章にまとめるだけ
毎朝動かすものに、広い権限を渡さない。
ステップ7:毎朝8時に動かす
毎朝動かすために、シェルスクリプトにする。
nano ~/morning-check/run_morning_check.sh
中身はこうする。
#!/bin/bash
set -e
CLAUDE=/Users/you/.local/bin/claude
RESULT=$(/Users/you/cbp-check/.venv/bin/python /Users/you/morning-check/scripts/morning_check.py)
printf '%s\n' "$RESULT" >> /Users/you/morning-check/logs/run.log
printf '%s\n' "$RESULT" | "$CLAUDE" --safe-mode -p "以下のJSONをもとに、会社員向けの朝レポートとして日本語で短くまとめて。必ず、確認日、重要ニュース、参考URLの変化、CBP最新PDF確認、商品ごとの確認結果、PDF URL、該当ページ、不明点、今日人間が見るべき点を含めて。数字は断定しすぎず、不明点は推測せず不明と書いて。" \
--output-format json \
--max-turns 5 \
--max-budget-usd 0.30 \
>> /Users/you/morning-check/logs/claude-results.jsonl
/Users/you/.local/bin/claude は、自分の環境に合わせる。
確認するには、次を実行する。
which claude
出てきたパスを、CLAUDE= に入れる。
実行権限を付ける。
chmod +x ~/morning-check/run_morning_check.sh
まず手で実行する。
~/morning-check/run_morning_check.sh
問題なければ、cronに入れる。
EDITOR=nano crontab -e
第4・5弾で
run_claude_check.shのcronをすでに設定している場合run_morning_check.shはCBP確認も含んでいるので、run_claude_check.shのcron行は削除してください。両方を同じ時間に動かすと、cbp_loop_check.pyが2回実行されてしまい、last_checked.jsonが意図しない状態になります。
毎朝8時なら、次の1行を入れる(既存の run_claude_check.sh の行があれば削除してから登録する)。
0 8 * * * /Users/you/morning-check/run_morning_check.sh
登録できたか確認する。
crontab -l
cronの詳しい説明は、第3弾で扱った。
ここでは、長いClaudeコマンドを直接cronに書かない。
run_morning_check.sh にまとめる。
その方が、あとで直しやすい。
補足:Windowsの場合 Windowsではcronではなく、タスクスケジューラを使う。長いコマンドを直接登録せず、
.batまたは.ps1にまとめてから毎朝8時に実行する。
4. 人間が見るべき場所
毎朝動くようになると、見ないといけない場所が分からなくなる。
だから、最初から見る場所を決める。
見るのは3つでいい。
| 見る場所 | 何を見るか |
|---|---|
reports/YYYY-MM-DD.md | 朝レポート |
logs/errors.log | 失敗がないか |
logs/claude-results.jsonl | Claudeの要約結果 |
CBPを使う場合は、第5弾の証跡も見る。
| 見る場所 | 何を見るか |
|---|---|
evidence/.../latest.pdf | 実際に確認したPDF |
evidence/.../metadata.json | PDF URL、SHA256、取得日時 |
logs/runs.jsonl | CBP確認の機械ログ |
AIの文章だけを見ない。
PDF URLを見る。 該当ページを見る。 不明点を見る。
これで、業務で説明できる。
5. この仕組みに、上級編の道具を当てはめる
ここまで来ると、上級編の道具がつながる。
| 回 | 道具 | 今回のどこに効いているか |
|---|---|---|
| 第1弾 | Plugin | この仕組みを将来まとめて配る |
| 第2弾 | Memory | 好み、判断基準、レポートの書き方を覚える |
| 第3弾 | Headless | claude -p で対話なしに実行する |
| 第4弾 | Loop Engineering | 前回状態を見て、変化を判断する |
| 第5弾 | ログ・証跡 | PDF URL、該当ページ、備考を残す |
| 第6弾 | 総合実践 | 毎朝の業務としてまとめる |
一点、混同しないようにしたい。
Memoryは、好みや判断基準を覚える場所だ。
たとえば、
朝レポートは短く。
不明点は必ず残す。
CBPの数字は断定しすぎない。
こういうものはMemoryに向く。
一方で、業務記録はMemoryに入れない。
今日見たPDF URL
SHA256
該当ページ
商品ごとの件数
これは、ログや証跡に残す。
Memoryとログは別物だ。
6. 失敗しやすいポイント
最後に、失敗しやすいところをまとめる。
1. ニュース元を増やしすぎる
最初から20個のニュース元を見ると、朝レポートが読めなくなる。
最初は3つでいい。
毎朝本当に見るものだけにする。
2. AIに自由検索させすぎる
「重要ニュースを探して」だけだと、毎日結果がぶれる。
この記事では、news_sources.txt に見る場所を固定した。
業務では、自由度を上げるより、再現性を上げる方が大事な場面が多い。
3. PDF URLを残さない
「SUGARは67件ありました」だけでは弱い。
PDF URL。 PDF日付。 該当ページ。 不明点。
ここまで残す。
4. エラーを消す
毎朝の処理では、エラーが出る。
RSSが落ちる。 ページが一時的に見られない。 PDFの形式が変わる。
その時に、エラーを消さない。
朝レポートに「人間が見るべき点」として残す。
5. cronに長いコマンドを直接書く
cronに長いClaudeコマンドを直接入れると、あとで直しづらい。
シェルスクリプトにまとめる。
cronは、それを呼ぶだけにする。
7. 今回のまとめ
上級編の最後に作ったのは、派手なAIアプリではない。
毎朝の確認業務を、静かに先回りする仕組みだ。
ニュースを見る。 参考URLを見る。 CBPの最新PDFを見る。 指定商品を見る。 PDF URLと該当ページを残す。 不明点を残す。 朝レポートにする。
この流れができると、AIの使い方が少し変わる。
毎回Claudeに頼むのではない。
Claudeが回る業務の形を、自分で設計する。
そして朝、人間はレポートを見る。
必要なところだけ判断する。
これが、上級編で目指していた形だ。
AIを使う人から、AIが回る仕組みを点検する人へ。
まずは、自分が毎朝見ているページを3つ選ぶ。
そこからでいい。