
シリーズ: Claudeで変わる仕事術 上級・第4弾 / 前回:上級・第3弾 “一行で起動”の次へ。最新PDFから指定商品の残量を毎朝チェックする
前回は、cronでClaude Codeを毎朝自動実行するところまで作った。「自分で起動する」作業はなくなった。でも、まだ弱いところがある。毎回、ゼロから同じ確認をしている。
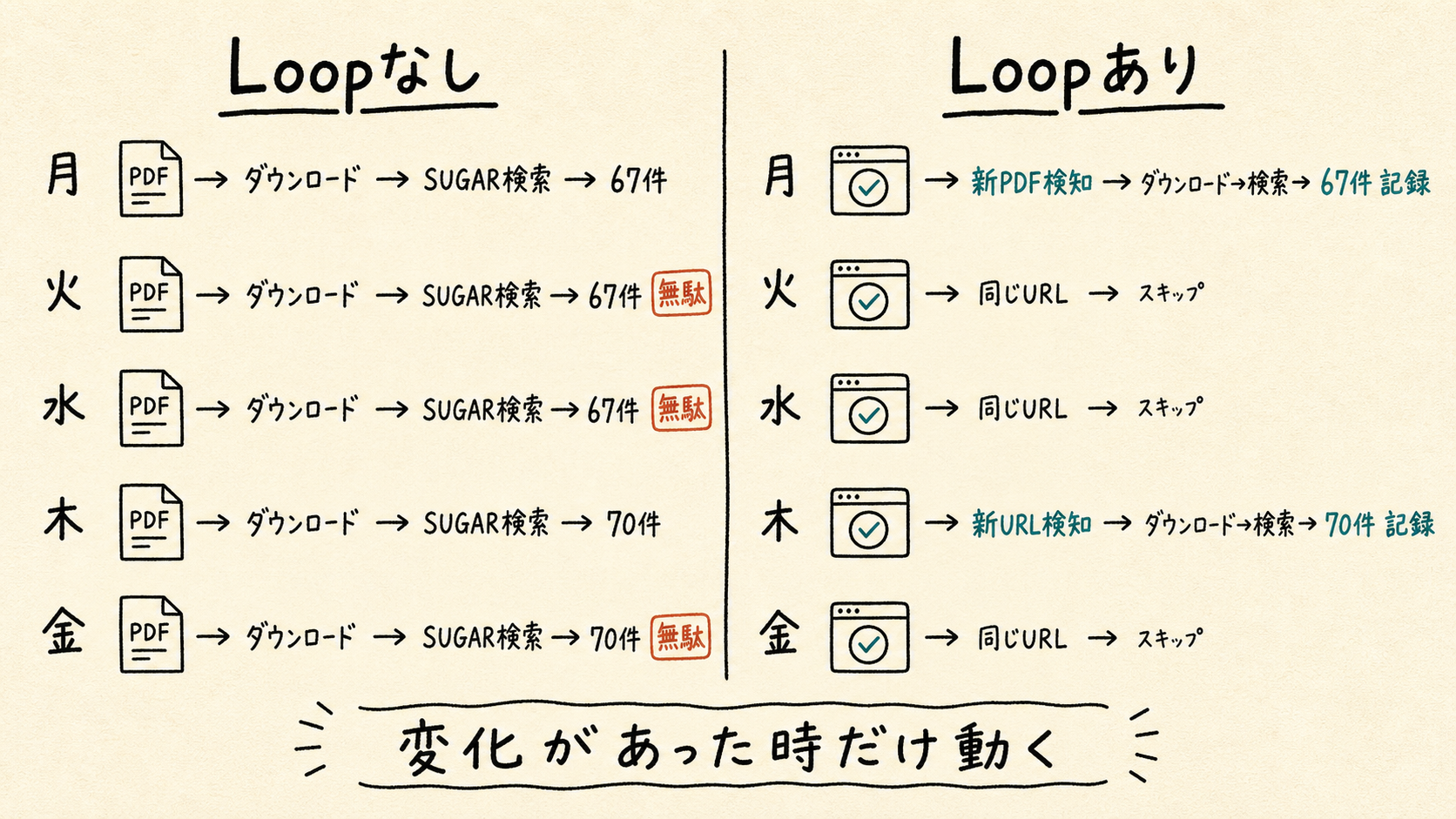
CBP確認を月〜金で見ると、こうなる。
第3弾のまま:
月:新PDF → ダウンロード → SUGARを探す → 67件
火:PDFは変わっていない → でもまたダウンロード → また67件
水: でもまたダウンロード → また67件
木:新PDF → ダウンロード → SUGARを探す → 70件
金:PDFは変わっていない → でもまたダウンロード → また70件
Loop化後:
月:新URL検知 → ダウンロード → 67件 → URL記録
火:URL確認 → 前回と同じ → スキップ(数秒で終わる)
水:URL確認 → 前回と同じ → スキップ
木:新URL検知 → ダウンロード → 70件 → URL更新
金:URL確認 → 前回と同じ → スキップ
前回のURLをファイルに残して次回起動時に比べる、それだけだ。変わっていなければスキップ、変わっていれば処理する。この「前回の状態を持って次回に引き継ぐ」発想が Loop Engineering である。
今回は第3弾のCBPスクリプトを、状態を持つLoopに育てる。
1. Loop Engineeringとは何か
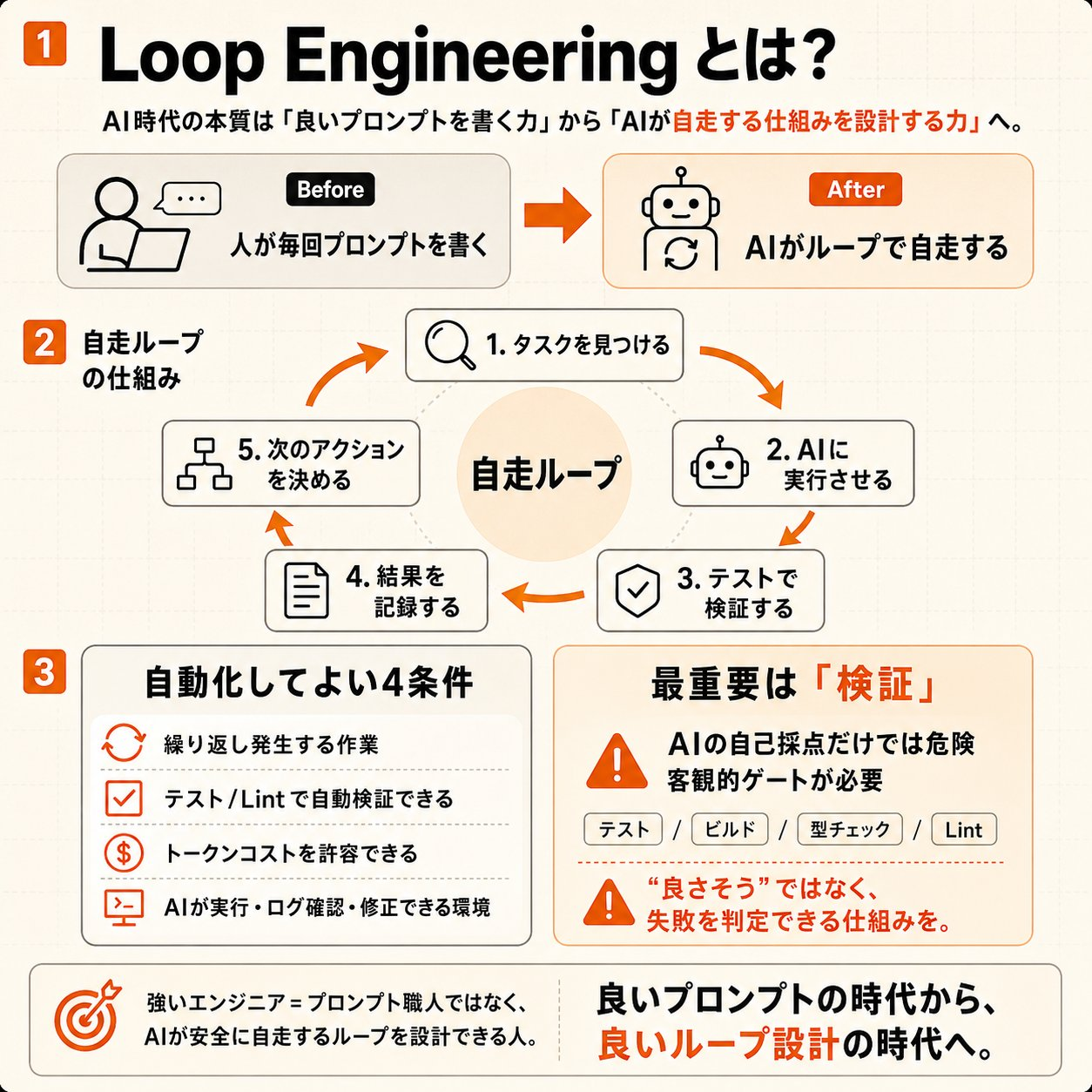
AIに一回頼むだけなら、Prompt Engineeringで十分だ。
このPDFを要約して
こう書けば、AIは一回だけ答える。
でも、実務では一回で終わらない仕事が多い。
- 毎朝・毎週・毎月、同じ場所を確認する
- 新しいものがあれば詳しく見て、なければ「変化なし」として残す
こういう仕事は、AIに毎回プロンプトを書くより、回る仕組みにした方がいい。
Loop Engineeringは、そのための考え方だ。
一言でいうと、こうだ。
AIに毎回お願いするのではなく、AIが読む状態・動く手順・止まる条件を設計すること。
ただし、Loopは「何でも自動でやってくれる魔法」ではない。
むしろ逆である。
Loopで大事なのは、自由に動かすことではなく、動ける範囲を狭く決めることだ。
2. cronとLoopは違う
前回使ったcronは、決まった時間にコマンドを動かす仕組みだ。
たとえば、毎朝8時にこのコマンドを動かす。
python3 cbp_check.py SUGAR
これは便利だ。
でも、cron自体は判断しない。
前回と同じPDFかどうか。 もう処理済みかどうか。 失敗した時に人間へ戻すべきかどうか。
cronはそこまで見ない。
cronは、ただの目覚まし時計だ。
Loopは、その後の判断まで含める。
| 項目 | cron | Loop Engineering |
|---|---|---|
| 役割 | 決まった時間に起動する | 状態を見て次の行動を決める |
| 前回結果 | 見ない | 状態ファイルを読む |
| 変化なし | 毎回同じ処理をする | スキップして記録する |
| 失敗時 | コマンドが落ちるだけ | 不明点として残す |
| 人間の確認 | 別で見る | 人間に戻す条件を決める |
つまり、第3弾は「毎朝起きる仕組み」だった。
第4弾は、「毎朝起きたあと、前回を見て動き方を変える仕組み」だ。
3. Loopに向く仕事、向かない仕事
Loopに向く仕事には、条件がある。
全部をLoopにしない。 ここを間違えると、便利になるどころか、確認するものが増える。
Loopに向くのは、次のような仕事だ。
| 条件 | 例 |
|---|---|
| 繰り返し発生する | 毎朝、毎週、毎月の確認 |
| 完了条件が書ける | 最新PDFが同じなら終了、新しければ確認 |
| 結果を検査できる | PDF URL、該当ページ、ログが残る |
| 失敗時に止められる | 読めない時は「人間確認」にする |
逆に、Loopにしない方がいい仕事もある。
- 発注する
- 申請する
- 契約する
- メールを送る
- 数字を最終判断する
- 顧客に回答する
ここは人間が持つ。
AIには、材料をそろえさせる。 判断は人間がする。
この線引きがあるから、業務で使える。
4. 今回作るもの
前回は、CBPのCommodity Status Reportページを見て、最新PDFから SUGAR を探した。
今回は、その確認をLoop化する。
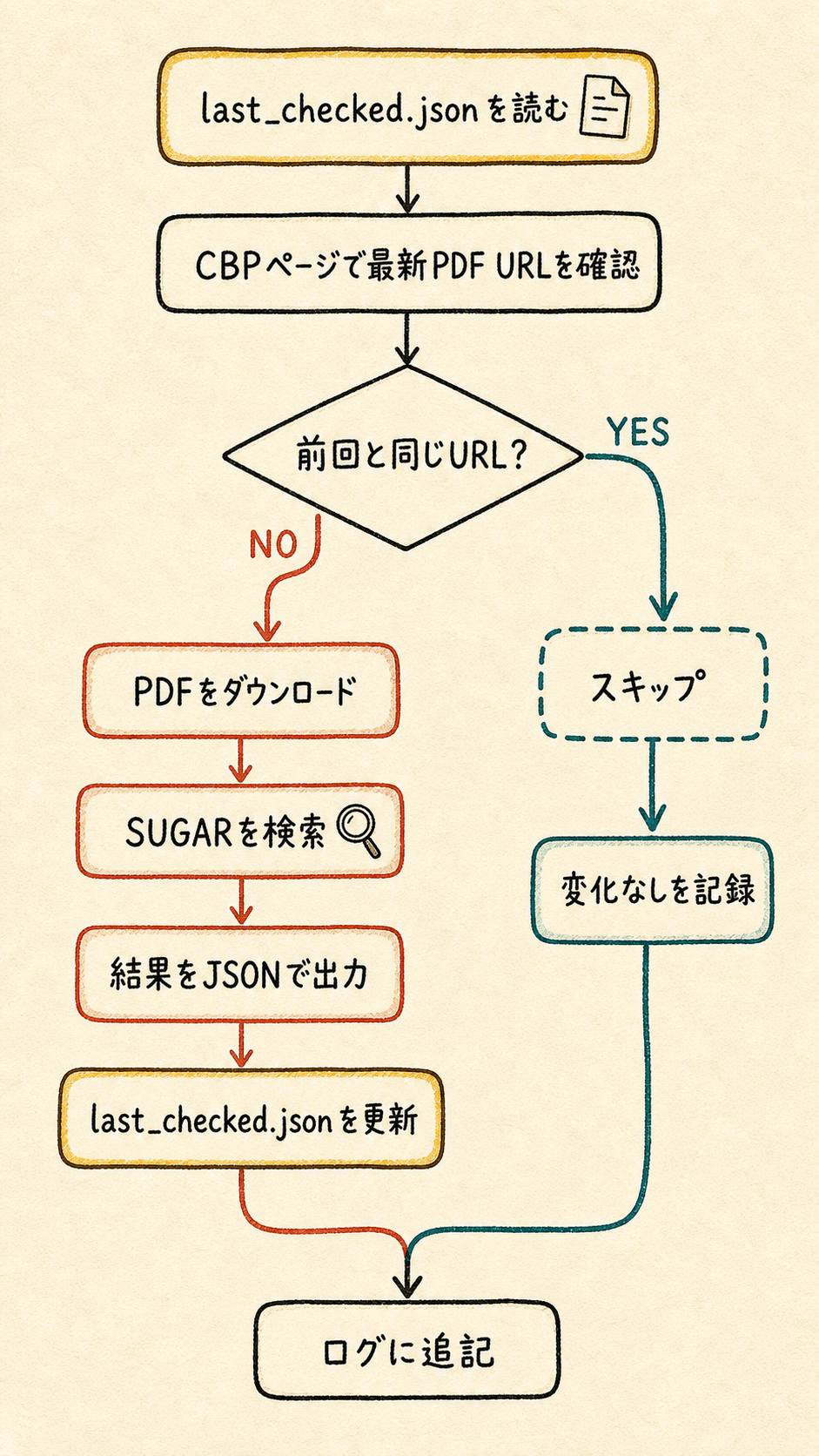
作る流れはこうだ。
前回の状態ファイルを読む
↓
CBPページから最新PDFを確認する
↓
前回と同じPDFか比べる
↓
同じなら「変化なし」で終了
↓
新しいPDFならダウンロードする
↓
指定商品を検索する
↓
結果をJSONで出す
↓
状態ファイルを更新する
使うファイルは3つだけだ。
| ファイル | 役割 |
|---|---|
cbp_loop_check.py | 最新PDFを確認し、前回との差分を見る |
last_checked.json | 前回確認したPDF URLや商品名を残す |
commodity-loop.log | Claudeがまとめた結果を追記する |
役割分担はこうだ。
Pythonが担う: URLの比較・PDFのダウンロード・商品の抽出・状態ファイルの更新 Claudeが担う: Pythonの出力(JSON)を人間が読みやすい日本語にまとめるだけ
判断はPythonがする。Claudeは変換係だ。
ポイントは、last_checked.json だ。
Claudeの会話に覚えさせるのではない。 ファイルとして残す。
Memoryは、好みや判断基準を覚える場所だ。 状態ファイルは、業務の事実を残す場所だ。
ここは分ける。
5. ハンズオン:CBP確認Loopを作る
ステップ1:作業フォルダとPython環境を作る
第3弾で ~/cbp-check を作った人は、そのまま使える。
まだ作っていない人は、先に作る。
mkdir -p ~/cbp-check
PDF処理には pdfplumber を使う。
前回そのまま python3 -m pip install pdfplumber とした人もいると思う。
ただ、Python環境によっては、依存ライブラリの不一致で動かないことがある。
仕事で毎日動かすなら、仮想環境を作る方が安定する。
cd ~/cbp-check
python3 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
python -m pip install pdfplumber
確認する。
~/cbp-check/.venv/bin/python -c "import pdfplumber; print('pdfplumber OK')"
pdfplumber OK と出れば大丈夫だ。

補足: すでに
python3にpdfplumberを入れている人でも、うまく動かない場合があります。 その場合は、この記事のように.venvを作り、以後は~/cbp-check/.venv/bin/pythonを使う方が安全です。
ここで、もう一つ準備をしておく。
後のステップでClaudeに実行を許可するコマンドをホワイトリストに書く。
--allowedTools "Bash(コマンド)" はスペースで複数ツールを区切る仕様のため、「Pythonのパス スクリプトのパス」と間にスペースが入るとパターンが崩れて毎回否認される。
そこで、Python呼び出しを1行にまとめた薄いラッパーを作る。
cat > ~/cbp-check/run_check.sh << 'EOF'
#!/bin/bash
exec ~/cbp-check/.venv/bin/python ~/cbp-check/cbp_loop_check.py "$@"
EOF
chmod +x ~/cbp-check/run_check.sh
これで run_check.sh SUGAR という一コマンドになり、ホワイトリストにスペースが入らない。
ステップ2:状態ファイル付きスクリプトを作る
新しく cbp_loop_check.py を作る。
nano ~/cbp-check/cbp_loop_check.py
開いたら、次のコードを貼り付ける。
import json
import re
import subprocess
import sys
from datetime import datetime
from pathlib import Path
from urllib.parse import urljoin
import pdfplumber
PRODUCT = sys.argv[1] if len(sys.argv) > 1 else "SUGAR"
PAGE_URL = "https://www.cbp.gov/document/report/commodity-status-report"
OUT_DIR = Path.home() / "cbp-check"
STATE_PATH = OUT_DIR / "last_checked.json"
PDF_PATH = OUT_DIR / "latest.pdf"
def load_state():
if STATE_PATH.exists():
return json.loads(STATE_PATH.read_text(encoding="utf-8"))
return {}
def save_state(state):
STATE_PATH.write_text(
json.dumps(state, ensure_ascii=False, indent=2),
encoding="utf-8",
)
def fetch_latest_pdf():
html = subprocess.check_output(
["curl", "-L", "--max-time", "30", "-s", PAGE_URL],
text=True,
)
match = re.search(
r'<a href="([^"]*commodity_status_report[^"]*\.pdf)">\s*([^<]+)\s*</a>',
html,
re.IGNORECASE,
)
if not match:
raise RuntimeError("No commodity status report PDF link found")
return {
"title": " ".join(match.group(2).split()),
"url": urljoin(PAGE_URL, match.group(1)),
}
def extract_matches(pdf_url):
subprocess.run(
["curl", "-L", "--max-time", "30", "-s", "-o", str(PDF_PATH), pdf_url],
check=True,
)
matches = []
with pdfplumber.open(PDF_PATH) as pdf:
for page_no, page in enumerate(pdf.pages, 1):
text = page.extract_text() or ""
for line in text.splitlines():
if PRODUCT.upper() in line.upper():
matches.append({
"page": page_no,
"line": " ".join(line.split()),
})
return matches
def needs_human(reason, extra=None):
result = {
"checked_at": datetime.now().isoformat(timespec="seconds"),
"product": PRODUCT,
"status": "needs_human",
"note": reason,
}
if extra:
result.update(extra)
print(json.dumps(result, ensure_ascii=False, indent=2))
def main():
OUT_DIR.mkdir(parents=True, exist_ok=True)
previous = load_state()
try:
latest = fetch_latest_pdf()
except Exception as e:
# PDF一覧を取得できない時は、状態ファイルを更新せず人間に戻す
needs_human(f"最新PDFを取得できなかった。人間確認が必要: {e}")
return
same_pdf = latest["url"] == previous.get("pdf_url")
same_product = PRODUCT.upper() == previous.get("product", "").upper()
should_extract = not (same_pdf and same_product)
try:
matches = extract_matches(latest["url"]) if should_extract else []
except Exception as e:
# PDFを読めない時も、状態ファイルを更新せず人間に戻す
needs_human(
f"PDFを読み取れなかった。人間確認が必要: {e}",
{"pdf_title": latest["title"], "pdf_url": latest["url"]},
)
return
status = "updated_pdf" if should_extract else "unchanged_pdf"
result = {
"checked_at": datetime.now().isoformat(timespec="seconds"),
"product": PRODUCT,
"status": status,
"previous_pdf_url": previous.get("pdf_url"),
"pdf_title": latest["title"],
"pdf_url": latest["url"],
"match_count": len(matches) if should_extract else previous.get("last_match_count", 0),
"matches": matches[:20],
"note": (
"PDF or product changed, extracted product lines"
if should_extract
else "PDF and product unchanged, skipped extraction"
),
}
save_state({
"checked_at": result["checked_at"],
"product": PRODUCT,
"pdf_title": latest["title"],
"pdf_url": latest["url"],
"last_status": result["status"],
"last_match_count": result["match_count"],
})
print(json.dumps(result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
保存する。
nanoなら、Ctrl + O、Enter、Ctrl + X だ。
このスクリプトは、第3弾の cbp_check.py と似ている。
違いは、前回の状態を読むところだ。
STATE_PATH = OUT_DIR / "last_checked.json"
このファイルに、前回見たPDF URLや商品名を残す。
次回実行した時に、同じPDFかどうかを比べる。
もうひとつのポイントは、PDFを取得・読み取りできなかった時の扱いだ。
この時は無理に処理を進めず、status を needs_human にして、状態ファイルも更新しない。
「読めなかった」という事実を残して、人間に判断を戻す。後述するセクション6の「人間に戻す条件」を、コード側でも守るためだ。
ステップ3:初回実行する
まずはClaudeを使わず、Pythonだけで動かす。
~/cbp-check/.venv/bin/python ~/cbp-check/cbp_loop_check.py SUGAR
初回は、まだ last_checked.json がない。
そのため、最新PDFを取りに行き、PDFの中から SUGAR を探す。
2026年6月30日に検証した時点では、最新PDFは次のものだった。
"checked_at": "2026-06-30T22:39:21",
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
実行すると、だいたい次のようなJSONが返る。
{
"checked_at": "2026-06-30T22:39:21",
"product": "SUGAR",
"status": "updated_pdf",
"previous_pdf_url": null,
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"match_count": 67,
"matches": [
{
"page": 2,
"line": "17010007CA05 Refined Sugar Canada CANADA - 202601 10/01/2025 09/30/2026 - 10300000 KG 10166558.6 98.70% POTF -"
},
{
"page": 2,
"line": "17010007CA05 Refined Sugar Canada - OTHR 202601 10/01/2025 09/30/2026 - 0 KG - 0.00% BAND -"
},
...
...
}
この時点で、last_checked.json も作られる。
中身を見てみる。
cat ~/cbp-check/last_checked.json
(.venv) junli@Juns-MacBook-Pro cbp-check % cat ~/cbp-check/last_checked.json
{
"checked_at": "2026-06-30T22:39:21",
"product": "SUGAR",
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"last_status": "updated_pdf",
"last_match_count": 67
}%
ステップ4:2回目を実行して、スキップされることを確認する
もう一度、同じコマンドを実行する。
~/cbp-check/.venv/bin/python ~/cbp-check/cbp_loop_check.py SUGAR
PDFが前回と同じなら、今度はPDFの中身を読み直さない。
結果はこうなる。
{
"checked_at": "2026-06-30T22:41:41",
"product": "SUGAR",
"status": "unchanged_pdf",
"previous_pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"pdf_title": "Quota Status Report: June 29 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_29.pdf",
"match_count": 67,
"matches": [],
"note": "PDF and product unchanged, skipped extraction"
}
これがLoopらしい動きだ。毎回がんばらない。変わった時だけ詳しく見て、変化がなければ「変化なし」という確認結果として残す。
ステップ5:Claudeに業務向けの言葉でまとめてもらう
ここでClaudeが登場する。
ただし、担当はここだけだ。
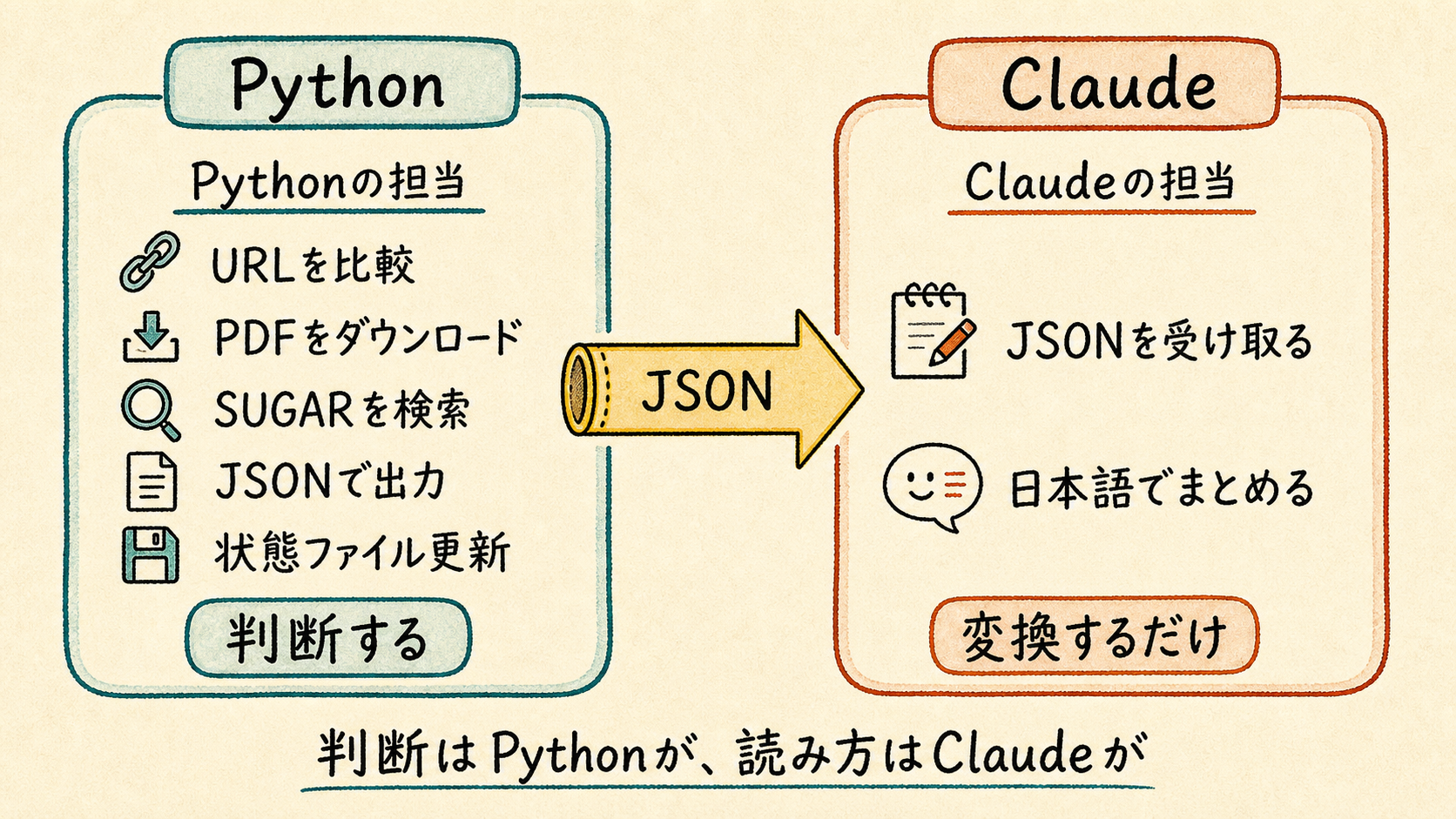
PythonのJSONは、機械には読みやすい。
でも、朝の業務メモとしては少し硬い。
そこでClaudeに、JSONを短くまとめてもらう。
ポイントは、パイプで渡すことだ。
run_check.sh → JSON出力 → パイプ → claude -p(要約のみ)
Claudeにはテキストを渡して、まとめるだけをやらせる。
Bashツールを触らせない。だから --allowedTools も --add-dir も不要だ。
~/cbp-check/run_check.sh SUGAR | claude -p "上記のJSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、status、PDFタイトル、PDF URL、商品名、該当件数、代表的な該当箇所、注意点。不明な点は推測せず「不明」と書いて。statusが unchanged_pdf の場合は、前回と同じPDFなので抽出をスキップした、と書いて。ただしPDF URLは必ず実際のURLを残して。" --output-format text
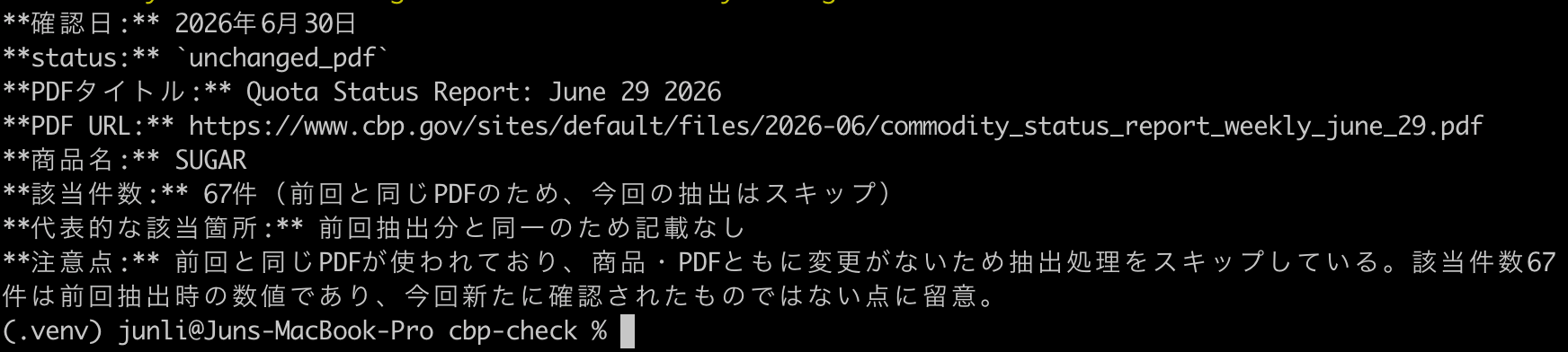
検証では、unchanged_pdf の結果を受け取り、Claudeは「前回と同じPDFなので抽出をスキップした」と要約できた。
ここで大事なのは、Claudeに「良さそうに要約して」と頼まないことだ。
必ず、残す項目を指定する。
確認日
status
PDFタイトル
PDF URL
商品名
該当件数
代表的な該当箇所
注意点
Loopが自走するほど、出力形式は固定した方がいい。
毎回違う書き方だと、人間が読む時に疲れる。
ステップ6:結果をログに残す
毎朝見るなら、結果をログに追記する。
まずは手動で試す。
~/cbp-check/run_check.sh SUGAR | claude -p "上記のJSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、status、PDFタイトル、PDF URL、商品名、該当件数、代表的な該当箇所、注意点。不明な点は推測せず「不明」と書いて。statusが unchanged_pdf の場合は、前回と同じPDFなので抽出をスキップした、と書いて。ただしPDF URLは必ず実際のURLを残して。" --output-format text \
>> ~/cbp-check/commodity-loop.log
ログを見る。
tail -n 40 /Users/you/cbp-check/commodity-loop.log
ログは、最初からきれいでなくてもいい。
最初に必要なのは、後から見返せることだ。
第5弾では、このログをさらに業務で使える証跡に整える。
ステップ7:毎朝の実行に組み込む
第3弾で run_cbp_check.sh を作った人は、その中身をこのLoop版に差し替えればいい。
新しく作るなら、こうする。
nano /Users/junli/cbp-check/run_cbp_loop.sh
中身はこうだ。
#!/bin/bash
/Users/you/cbp-check/run_check.sh SUGAR \
| /Users/you/.local/bin/claude -p "上記のJSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、status、PDFタイトル、PDF URL、商品名、該当件数、代表的な該当箇所、注意点。不明な点は推測せず「不明」と書いて。statusが unchanged_pdf の場合は、前回と同じPDFなので抽出をスキップした、と書いて。ただしPDF URLは必ず実際のURLを残して。" \
--output-format text \
>> /Users/you/cbp-check/commodity-loop.log 2>&1
/Users/you/.local/bin/claude は、自分の環境に合わせる。
確認するには、次を実行する。
which claude
出てきたパスを、シェルスクリプトに入れる。
実行権限を付ける。
chmod +x /Users/you/cbp-check/run_cbp_loop.sh
手動で試す。
/Users/you/cbp-check/run_cbp_loop.sh
問題なければ、crontabに入れる。
EDITOR=nano crontab -e
毎朝10時なら、次の1行を入れる。
0 10 * * * /bin/bash /Users/you/cbp-check/run_cbp_loop.sh
これで、毎朝10時に起動する。
6. Loopで必ず決める4つの線
Loopを作る時は、必ず4つの線を決める。
1. 成功条件
何をもって成功とするか。
今回なら、こうだ。
最新PDF URLを確認できた
前回と同じか判定できた
新しいPDFなら指定商品を検索できた
結果をJSONで返せた
状態ファイルを更新できた
2. 停止条件
どこで止めるか。
PDFが前回と同じなら終了
指定商品が見つからなければ「該当なし」で終了
PDFが読めなければ「人間確認」で終了
最大ターン数は5
予算上限は0.20ドル
3. 権限
何を許可するか。
今回はパイプ構成のため、Claudeにはテキストだけを渡す。
Bashツールを使わせない。--allowedTools の指定は不要だ。
データ収集(Python)と要約(Claude)を分けたことで、Claudeの権限はゼロになる。メール送信もファイル削除も、社内システムへの書き込みもしない。
4. 人間に戻す条件
AIが判断してはいけないところを決める。
PDFが取得できない
商品名が複数の意味でヒットする
数字の列が読み取れない
残量なのか使用済み数量なのか曖昧
発注や社内判断が必要
この時は、AIに決めさせない。
「人間確認」として残す。
7. よくある失敗
Loopで失敗する時は、だいたい原因が決まっている。
失敗1:状態ファイルがない
状態ファイルがないと毎回初回実行になる。昨日何を見たかわからないまま、毎朝同じPDFを読み直す。ただの繰り返しだ。
失敗2:停止条件がない
「できるまで頑張って」と書くと危ない。
AIは、いつ止まればいいか分からない。
今回はパイプ構成のため、Claudeはテキストを受け取って一度だけ答えて終わる。 ツールを呼ばないので、ターン数の膨張は起きない。
ただし、Claudeに複数ターンで作業させる設計(ツール利用・エージェント)に戻す時は必ず上限を入れる。
--max-turns 5
--max-budget-usd 0.20
失敗3:AIが自分で自分を採点する
AIに「ちゃんとできた?」と聞くと、だいたい「できました」と返る。
仕事では、それだけでは足りない。
今回なら、客観的に残すものを決める。
- PDF URL
- PDFタイトル
- status
- match_count
- 該当ページ
- 状態ファイル
- ログ
見返せるものがあるから、人間が確認できる。
失敗4:いきなり送信までやらせる
最初からSlackに送る、メールする、社内システムに書く、これは早い。
まずは、ログに残すだけでいい。
数日見て、出力が安定してから次へ進む。
8. 今回のまとめ
第3弾では毎朝動かした。第4弾では、そこに「状態を持つ」を足した。これがLoop Engineeringの第一歩だ。
大事なのは、AIに自由を与えることではない。前回の状態・今回の手順・止まる条件・人間に戻す条件、これを先に決めることだ。
仕事で使える自動化は、派手な全自動ではない。
前回を覚えて、必要な時だけ動き、根拠を残す仕組みである。
次回は、ここからさらに一歩進める。
Loopが出した結果を、業務で説明できる証跡にする。
PDF URL、該当ページ、ログ、不明点。
AIの要約を、仕事で使える記録に変えていく。